|
|
Documenting Mayan Language Acquisition
Clifton Pye
The University of Kansas
November 15, 2005
(revised December 3, 2006)
Project Description
Chomsky has long stressed the significance of the fact that children can acquire any human language. This childhood phenomenon is a central motivation in the search for language universals. The other side of the generative program is the need to document the full range of language diversity while typologically distinct languages still exist. Such documentation is necessary to understand the true nature of children’s linguistic accomplishments. The present proposal seeks to document the acquisition of three Mayan languages.
The Mayan world is undergoing rapid political and economic change. At present many men between seventeen and forty years of age have migrated to the United States from towns and villages throughout Mexico and Guatemala. The last decade has also brought a greater intrusion of Spanish into remote Mayan communities in the form of satellite and cable television programming. It is a critical time to document the acquisition of Mayan languages while there are still children acquiring them in traditional settings.
Mayan languages differ from European languages on many key linguistic dimensions. Mayan languages employ a contrast between plain and glottalized consonants, lacking a series of voiced stops. Mayan languages have full or partially ergative cross-reference systems. The languages with partially ergative systems ‘split’ by person, aspect or clause type. The languages usually have multiple types of passive and antipassive constructions which combine with syntactic movement to focus on the subject or object of a clause. The languages also contain verbal and/or nominal classifiers.
The linguistic features of Mayan languages raise fundamental issues for theories of linguistics and language acquisition. The project will advance theoretical models in both domains by documenting the acquisition of three Mayan languages. A further goal of the project is to establish a comparative acquisition base for the Mayan languages to facilitate comparison between processes of historical change and language acquisition. The comparative perspective makes it possible to apply theoretical and descriptive insights from the acquisition of one language to the understanding of the acquisition process in related languages.
Equipment
Recording technology is undergoing rapid changes to a solid state digital format. This format has the great advantage of reducing the number of moving parts in the equipment, thus reducing the noise generated by the equipment itself. The disadvantage with this format is that it requires a good deal of research to discover which recording format is best suited to producing high quality recordings.Our key discoveries were the need for 16 or 24 bit audio recordings at 44.1 kHz and a 3-CCD style video recording technology. Microphones are crucial to any recording technology, and we also found information on the types of audio and video microphones. The following sources were a great help to us in identifying appropriate recording formats.
Heidi Johnson at the The Archive of the Indigenous Languages of Latin America provided many helpful suggestions.
Bartek Plichta is a phonetician who tests various kinds of recording equipment.
E-MELD also provides some basic hardware recommendations on its webpage.
CHILDES has some basic recording recommendations on its webpage, but these are now out of date.
The Max Planck Institute for Psycholinguistics has a webpage with information on hardware and their own tools for processing video and audio recordings.
The project will make use of state-of-the-art video and audio technology to record children’s language in remote, rural settings. The recording conditions impose severe restrictions on the type of equipment we are using. It must be light-weight, battery-operated equipment that will tolerate hot, cold and wet conditions. We are using the following items for our project.
Audio Recordings
We are using the Edirol R-1 wave recorder. This is a solid-state recorder that makes recordings at either 16 or 24 bits at 44.1 kHz. The Edirol records onto a CompactFlash card. It accepts up to a 4 GB card, but a 1 GB card will record for 90 minutes at the 16 bits. The Edirol has two crucial limitations. It uses batteries at a rapid rate. We have found that it can only record for one hour at 16 bits before the batteries are used up. We have purchased rechargeable batteries to reduce this problem. The other limitation is that the Edirol limits the volume of the recording to reduce clipping. The recording must first be normalized and then it can be amplified as much as needed. We are using the Cool Edit 2000 program to normalize and amplify the recordings.
The Edirol has a built in stereo microphone, but adding an external microphone considerably improves the quality of the recording. We have found the SONY ECM-MS907 microphone adequate for this purpose. The Edirol has a switch with dynamic and condensor microphone settings. The condensor setting will provide phantom power to the external microphone, but does not function when the external microphone has its own power source. To save battery life, we use the dynamic setting with externally powered condensor microphones.
Video Recordings
We selected the Panasonic PV-GS150 mini-dv video camera for this project. The GS150 has a 3-CCD video recording system, and allows the audio recording to be made at 16 bits at 44.1 kHz. The camera also comes with a jack for an external microphone. We are using the SONY ECM-MS908C video microphone. The battery that comes with the camera will record for an hour, but a larger battery (ER-C535) allows the camera to operate up to 4 hours. The Panasonic comes with its own software program for transferring the recordings to a computer via a high-speed USB cable. We are using the Adobe Premiere Element program to record the videos onto DVDs. The camera also has a firewire jack to transfer recordings directly to a DVD recorder.
Microphones
We found information on the following microphones:
Audio
SONY ECM MS957
SONY ECM MS907
Video
SONY ECM MS908C
Sennheiser MKE 300
All of these microphones have a 1/8" microphone jack that is compatible with the Edirol and Panasonic recorders. You should also get a shielded extension cable for the microphones.
Transcription
We have been using SoundScriber to transcribe the video and audio recordings. This program accepts many different formats, and allows the user to control the length of time, and number of times the program plays each segment. We can then transcribe the tapes using the Notepad program while SoundScriber plays the recording continuously. We use the program Adobe Premiere elements to export the video recordings to the mpeg1 format that SoundScriber can play. The mpeg1 format allows us to transcribe the video recordings with SoundScriber.
We are following the minimal transcription procedure developed by Pye, but with a few modifications. Minimal coding starts with a transcription of the language sample that includes at least a speaker identification label for each speaker in the sample. We list the speakers at the beginning of the transcription with an initial capital letter followed by the rest of the name in parentheses, e.g. C(hild). Each utterance in the transcript begins with a speaker code that consists of the upper case letter followed by a space and then that speaker's utterance, e.g.
C ewtyi’
Where the children’s utterances differ from the adult equivalent, we add an equivalence line. This line begins with a space, an equal sign and a space followed by the adult equivalent, e.g.
= jatyety.
It is only necessary to add an equivalence line for the children’s utterances which differ from the adult form. An example of a full transcription would go as follows:
C(hild’s name)
A(dult’s name)
X(unknown speaker)
+ February 26, 2006
A uy cha’p’ej k’ele cha’p’ej.
A uno, dos, dos k’ele dos ya’añ.
C ej.
= (cha’p’ej.)
C ewtyi’.
= jatyety.
A ches ityuñ ili.
A uy k’ele.
All lines that begin with a plus (‘+’) indicate information that will not be processed by the analysis programs, e.g., comment lines and information about the child and the transcription. The transcription can also include blank lines. Information about doubtful transcriptions or interpretations should be enclosed in parentheses.
Once the transcription is completed, we use the program ‘Qanform’ to add additional tiers to each speaker line in the original transciption. It is necessary to convert the transcription to a text format before using the program Qanform. If you are using Word for to transcribe recordings, you can use the ‘save as’ option to save a copy of the transcription as ‘plain text’. Use the Windows option, and be sure to check the ‘Insert line breaks’ box to end all lines with ‘CR/LF’. Once you have saved the file in this format it is also necessary to exit Word completely. Text files have the extension ‘.txt’. The Qanform program does not accept files with names that have more than eight characters or special characters. It also does not accept files names with multiple extensions, e.g. ‘filename.doc.txt’. It is best to restrict file names to a combination of letters and numbers, e.g. ‘file1106.txt’.
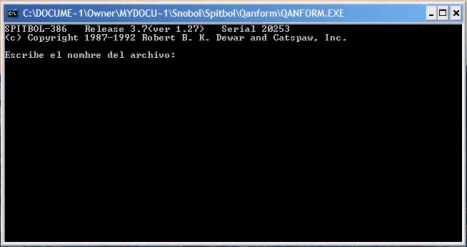
The Qanform program can be run by double clicking on the program icon. That action should produce a window like the following:
|
|
On some computers, the program will not run when it is saved in a folder too far down in the computer’s directory. If you have this problem, move the folder with the program to the computer’s desktop. Once you see this window, type in the name of the file, e.g. ‘Test351.txt’. Be careful to type in both the filename and the ‘.txt’ extension, and press the ‘enter’ key. The program is not case sensitive. The program will then ask for the subject’s initial. Type the initial, e.g. ‘C’ and press the enter key. The program will generate a new file with the same filename as the original, but with the extension ‘.out’. An example of the output is shown below:
C(hild’s name)
A(dult’s name)
X(unknown speaker)
+ February 26, 2006
A uy cha’p’ej k’ele cha’p’ej.
%mor uy cha’p’ej k’ele cha’p’ej.
%eng
%spa
A uno, dos, dos k’ele dos ya’añ.
%mor uno, dos, dos k’ele dos ya’añ.
%eng
%spa
C ej.
= (cha’p’ej.)
%mor (cha’p’ej.)
%eng
%spa
C ewtyi’.
= jatyety.
%mor jatyety.
%eng
%spa
A ches ityuñ ili.
%mor ches ityuñ ili.
%eng
%spa
The Qanform program adds three tiers to each speaker line in the original file. We use the ‘%mor’ tier to code morphemes and the ‘%spa’ tier for a Spanish translation, but the investigator is free to use the tier in any manner they wish.
Analysis
Once the transcription has been expanded in this manner, it can be analyzed using the other programs in the Qanform suite. All of the programs run in their own window, and ask for the name of the file being analyzed and the speaker’s initial. Remember that the new file has an ‘.out’ extension, e.g. ‘Test351.OUT’.
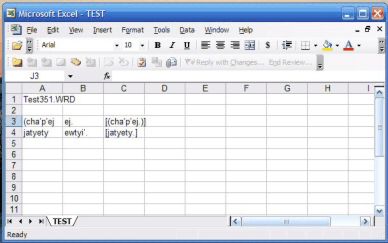
We use the program Palabra to extract the words for each speaker. The program can be run by double clicking the palabra icon. The program requests the name of the subject’s file (with its extension) and then the subject’s initial. With the ‘Test351.OUT’ as its input, it produces the file ‘Test351.WRD’ as output. The output is arranged in three columns separated by tabs. The adult form of the word appears in the first column, the child’s production in the second, and the information in the morphological tier in the third column, e.g.
(cha’p’ej ej. [(cha’p’ej.)]
jatyety ewtyi’. [jatyety.]
The output is difficult to read as a text file, but it is in a form that can be input directly into an Excel spreadsheet. To see the file in Excel, open the Excel program and click the ‘open file’ icon. It is necessary to change the file type to ‘All Files’ before the wrd file will appear in the Excel window. If the file extension is not visible, it will appear when you hold the cursor over its image for a second. Select the file and click ‘Open’. This action opens the ‘Text Import Wizard’. Choose the ‘Delimited’ open and click ‘Next >’. Click the ‘Tab’ option and click ‘Next >’. Excel then asks you to select a format option for each column in the file. It is best to select ‘Text’ for each column with data. After formatting each column, select ‘Finish’. You should see the data appear in three separate columns, as in the following figure.
|
|
We found that the Excel program has many advantages for analyzing data files. The user can add as many rows and columns as necessary for analysis. We put a one in each column for each specific analysis, e.g. the monosyllabic words, the words with an initial consonant, etc. Selecting that column then provides a quick count of the number of words that meet each criterion. The ‘Sort’ function in Excel can be used to sort the words in either the adult column or the child column. We recommend experimenting with the Excel program to see how it can facilitate data analysis.
We use Pye’s minimal coding method to code the children’s morphology on the %mor tier. We mark omitted morphemes with an asterisk ‘*’ and verb roots with a slash ‘/’. We use the exclamation sign ‘!’ to mark overgeneralized morphemes. A transcript with this coding is shown below:
C(hild)
A(dult)
+ October 10, 2005
A ma chb’eyi?
%mor ma chb’eyi?
%eng
%spa
C payi.
= chb’eyi.
%mor *ch-*0-/b’ey-i.
%eng
%spa
A majxa hach toq?
%mor majxa hach toq?
%eng
%spa
C hintoj.
= qin toq.
%mor *q-in /toq.
%eng
%spa
A yul kan.
%mor yul kan.
%eng
%spa
C wul kan.
= yul kan.
%mor !w-ul kan.
%eng
%spa
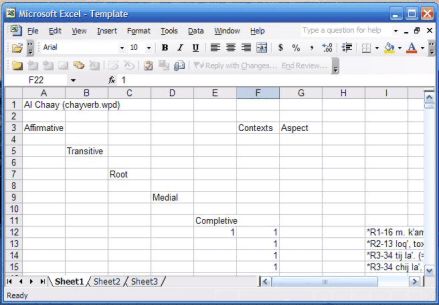
With the morphology coded in this fashion, we use the program Qanverb to extract all of the verbs produced by the child. Qanform writes its output to the file ‘file.VRB’. The program outputs the child’s production for each verb separately followed by the morphological coding and a one, as shown below:
b'ey
payi. (=*ch-*0-/b'ey-i.) 1
toq
hintoj. (=*q-in /toq.) 1
This output can be opened in Excel like the output from the Palabra program, making it possible to sort the children’s verbs by transitivity and aspect, as in the following example:
|
|
Some experimentation is necessary to see the advantages of this process. The main advantage is that the children’s data is arranged in a transparent manner that is easy to check and analyze.
Manual del Campo (Field Manual)
Tenemos un manual del campo en espanol que describe nuestras experiencias. Este manual fue escrito por Pedro Mateo.
Elicitacion de Palabras
Tenemos una lista de palabras que queremos usar para elicitar palabras en los tres idiomas. Estamos buscando debujos para cada palabra.