
Computational Linguistics
The image of humans conversing with their computers is both a thoroughly accepted cliche of science fiction and the ultimate goal of computer programming, and yet, the year 2001 has come and gone without the appearance of anything like the HAL 9000 talking computer featured in the movie 2001: A Space Odyssey.
Computational linguists attempt to use computers to process human languages. The field of computational linguistics has two general aims:
The technological. To enable computers to analyze and process natural language.
The psychological. To model human language processing on computers.
From the technological perspective, natural language applications include:
Speech recognition. Today, many personal computers include speech recognition software.
Nicole Yankelovich, Gina-Anne Levow, and Matt Marx provide a discussion of the challenges of speech recognition.
Examples of speech recognition errors can be found on Susan Fulton’s web site.
Conversay provides this infomercial on their speech recognition product.
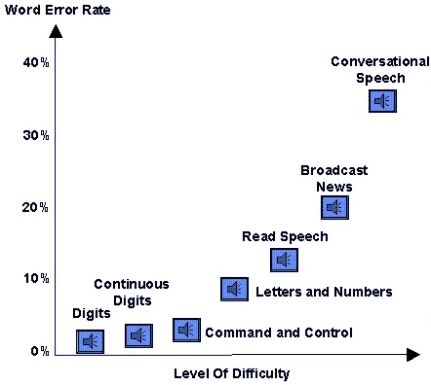
Hao Tang created this chart of the relation between speech recognition errors and linguistic task:
Speech Synthesis. Computers have also achieved variable success in producing speech.
Gregor Möhler’s web site provides a comprehensive list of synthesis software.
ATT Labs’ web site provides a demonstration of their program.
Natural language interfaces to software. For example, demonstration systems have been built that let a user ask for flight information.
Examples:
chatterbots, e.g., Alice
natural language understanding, e.g., a perl parser
Document retrieval and information extraction from written text. For example, a computer system could scan newspaper articles, looking for information about events of a particular type and enter the information into a database.
Examples:
web searches, e.g., google.
course information and enrollment, e.g., KU, Linguistics.
Machine translation. Computers offer the promise of quick translations between languages.
Examples:
machine translation, e.g., SDL International
The rapid growth of the Internet/WWW and the emergence of the information society poses exciting new challenges to computational linguistics. Although the new media combine text, graphics, sound and movies, the whole wealth of multimedia information can only be structured, indexed and navigated through language. For browsing, navigating, filtering and processing the information on the web, we need language technology. The increasing multilingual nature of the web constitutes an additional challenge for language technology. The multilingual web can only be mastered with the help of multilingual tools for indexing and navigating.
Computational linguists adopting the psychological perspective hypothesize that at some abstract level, the brain is a kind of biological computer, and that an adequate answer to how people understand and generate language must be in terms formal and precise enough to be modeled by a computer.
ELIZA
Natural language processing comes in many varieties. The most robust natural language systems are tailored to the most limited applications. The simplest approach to natural language processing is to program the computer to look for a limited set of key words or phrases. When the computer finds these words it produces a programmed response. The ELIZA program offers a particularly compelling example of the keyword approach to natural language processing. ELIZA was written at MIT in the mid-1960s to mimic the role of a psychoanalyst interviewing a patient. Examples of ELIZA and related programs are now widely available on the web and personal computers.
ELIZA was never intended to be a model of natural language understanding, yet it is still one of the most popular artificial intelligence programs in the public domain. As long as the user accepts the premise that the program is conducting an open-ended interview, ELIZA can produce a convincing imitation of a talking computer. ELIZA works by searching for a list of keywords in the input. If the program finds one of these words, it asks a preprogrammed question that centers around the keyword. If the program does not find a word on its list, it chooses from a set of open-ended responses, such as Tell me more or Go on. Here is an example of a dialogue with ELIZA. The transcript appears to show that ELIZA responds to user input in a semi-intelligent fashion. If only all computer operating systems were this helpful!
A conversation with ELIZA
|
Eliza |
Hello. I am ELIZA. How can I help you? |
|
You |
What help can you provide? |
|
Eliza |
Does that question interest you? |
|
You |
Why do you ask? |
|
Eliza |
Oh, I ask. |
|
You |
I believe you said you could help me. |
|
Eliza |
Do you wish to believe me? |
|
You |
Yes. |
|
Eliza |
You are sure? |
|
You |
Why wouldn't I be sure? |
|
Eliza |
Can you elaborate on that? |
Once you understand how ELIZA operates, though, you realize how the appearance of intelligence in ELIZA’s responses is only supplied by the user and any onlookers. Figure 1.2 displays a fragment of an ELIZA database of keywords. The database contains keywords in contexts represented by variables. The variables are patterns that match portions of the input sentence. This pattern-matching technique allows the program to formulate a response that rearranges parts of the input sentence. For example, ELIZA would apply the pattern
X are you Y
to the input Why are you talking to me? The variable X in the pattern would match the word why in the input while the variable Y in the pattern would match the words talking to me. ELIZA would then use this pattern match to generate the response Would you prefer it if I weren’t talking to you? where the words in Y are attached to the end of the phrase Would you prefer it if I weren’t with some adjustments for the pronouns.
Sample response patterns for ELIZA
|
Keyword |
Pattern |
Response |
|
alike |
X |
In what way? What resemblance do you see? |
|
are |
X are Y |
What if they were not Y? |
|
are you |
X are you Y |
Would you prefer it if I weren’t Y? |
|
always |
X |
Can you think of a specific example? When? Really, always? |
ELIZA provides an excellent example of the pattern-matching approach to natural language processing. Programmers can construct patterns that match simple phrases, and then embed these patterns in more complex patterns that search for contexts in which the simple phrases occur. I will rely on pattern-matching techniques to illustrate various aspects of natural language systems. Pattern-matching is the most widely used programming technique in natural language systems. It is obvious that ELIZA, though, is not using pattern-matching to perform any understanding of the language input. The program responds in rote fashion to any input, and even its use of multiple responses to the same pattern do not qualify as intelligent.
A few tricks quickly expose the limits of ELIZA’s linguistic ability. If you supply ELIZA with one of its keywords in an unusual context, the program will produce an inappropriate response. For example, if you type Necessity is the mother of invention, the program might respond with Tell me more about your family, based on the pattern match with the keyword mother. Since the program lacks any knowledge of sentence structure, it is incapable of responding sensibly to keywords with modifiers. If you input the sentence Computers make unrealistic mothers, the program might still respond with a request to learn more about your mother. Since the program doesn’t really process language at all, offering it gibberish will only succeed in generating more gibberish rather than an admonishment to use correct English. For example, the input Xsdf theos are you vowmpss ssoov might trigger the output Would you prefer it if I weren’t vowmpss ssoov? More generally, the program only requests more information from the user, it cannot supply any information about itself. ELIZA evades all such questions by responding with another question, Why do you ask? If you enter the same sentence two, three or four times in a row, ELIZA will treat each repetition as a new response. The program was not designed to track information over the course of an entire conversation.
ELIZA teaches several lessons about natural language programming and more generally about the field of artificial intelligence. The technique of pattern matching can produce impressive results with a simple program AS LONG AS the application is highly restricted. As soon as we try to venture outside the boundaries of the program we quickly recognize the computer’s limitations. The key to evaluating any natural language system is to test its boundaries. The key ingredient that ELIZA and all other computer programs currently lack is a true understanding of natural language.
Problems in Computational Linguistics
From both perspectives, a computational linguist will try to develop a set of rules and procedures, e.g. to recognize the syntactic structure of sentences or to resolve the references of pronouns. One of the most significant problems in processing natural language is the problem of ambiguity.
In
(1) I saw the man in the park with the telescope.
it is unclear whether I, the man, or the park has the telescope.
If you are told by a fire inspector,
(2) There's a pile of inflammable trash next to your car. You are going to have to get rid of it.
whether you interpret the word ‘it’ as referring to the pile of trash or to the car will result in dramatic differences in the action you take. Ambiguities like these are pervasive in spoken utterances and written texts.
Another example is the sentence ‘Many elephants smell.’ It could mean:
Many elephants smell bad, or
Many elephants smell (food)
Human speakers would use the discourse context to decide which reading was appropriate.
Most ambiguities escape our notice because we are very good at resolving them using our knowledge of the world and of the context. But computer systems do not have much knowledge of the world and do not do a good job of making use of the context.
Approaches to Ambiguity
Efforts to solve the problem of ambiguity have focused on two potential solutions: knowledge-based and statistical.
In the knowledge-based approach, the system developers must encode a great deal of knowledge about the world and develop procedures to use it in determining the sense of texts. For the second example above, they would have to encode facts about the relative value of trash and cars, about the close connection between the concepts of 'trash' and 'getting rid of', about the concern of fire inspectors for things that are inflammable, and so on. The advantage of this approach is that it is more like the way people process language and thus more likely to be successful in the long run. The disadvantages are that the effort required to encode the necessary world knowledge is enormous, and that known procedures for using the knowledge are very inefficient.
In the statistical approach, a large corpus of annotated data is required. The system developers then write procedures that compute the most likely resolutions of the ambiguities, given the words or word classes and other easily determined conditions. For example, one might collect Word-Preposition-Noun triples and learn that the triple <saw, with, telescope> is more frequent in the corpus than the triples <man, with, telescope> and <park, with, telescope>. The advantages of this approach are that, once an annotated corpus is available, the procedure can be applied automatically, and it is reasonably efficient. The disadvantages are that the required annotated corpora are often very expensive to create and that the methods will yield the wrong analyses where the correct interpretation requires awareness of subtle contextual factors.
Machine Translation
At the end of the 1950s, researchers in the United States, Russia, and Western Europe were confident that high-quality machine translation (MT) of scientific and technical documents would be possible within a very few years. After the promise had remained unrealized for a decade, the National Academy of Sciences of the United States published the much cited but little read report of its Automatic Language Processing Advisory Committee. The ALPAC Report recommended
that the resources that were being expended on MT as a solution to immediate practical problems should be redirected towards more fundamental questions of language processing that would have to be answered before any translation machine could be built. The number of laboratories working in the field was sharply reduced all over the world, and few of them were able to obtain funding for more long-range research programs in what then came to be known as computational
linguistics.
There was a resurgence of interest in machine translation in the 1980s and, although the approaches adopted differed little from those of the 1960s, many of the efforts, notably in Japan, were rapidly deemed successful. This seems to have had less to do with advances in linguistics and software technology or with the greater size and speed of computers than with a better
appreciation of special situations where ingenuity might make a limited success of rudimentary MT. The most conspicuous example was the METEO system, developed at the University of Montreal, which has long provided the French translations of the weather reports used by airlines, shipping companies, and others. Some manufacturers of machinery have found it
possible to translate maintenance manuals used within their organizations (not by their customers) largely automatically by having the technical writers use only certain words and only in carefully prescribed ways.
Why Machine Translation Is Hard
Many factors contribute to the difficulty of machine translation, including words with multiple meanings, sentences with multiple grammatical structures, uncertainty about what a pronoun refers to, and other problems of grammar. But two common misunderstandings make translation seem altogether simpler than it is. First, translation is not primarily a linguistic operation, and second, translation is not an operation that preserves meaning.
There is a famous example that makes the first point well. Consider the sentence:
The police refused the students a permit because they feared violence.
Suppose that it is to be translated into a language like French in which the word for 'police' is feminine. Presumably the pronoun that translates 'they' will also have to be feminine. Now replace the word 'feared' with 'advocated'. Now, suddenly, it seems that 'they' refers to the students and not to the police and, if the word for students is masculine, it will therefore require a different translation. The knowledge required to reach these conclusions has nothing linguistic about it. It has to do with everyday facts about students, police, violence, and the kinds of relationships we have seen these things enter into.
The second point is, of course, closely related. Consider the following question, stated in French: Ou voulez-vous que je me mette? It means literally, "Where do you want me to put myself?" but it is a very natural translation for a whole family of English questions of the form "Where do you want me to sit/stand/sign my name/park/tie up my boat?" In most situations, the English "Where do you want me?" would be acceptable, but it is natural and routine to add or delete information in order to produce a fluent translation. Sometimes it cannot be avoided because there are languages like French in which pronouns must show number and gender, Japanese where pronouns are often omitted altogether, Russian where there are no articles, Chinese where nouns do not differentiate singular and plural nor verbs present and past, and German where flexibility of the word order can leave uncertainties about what is the subject and what is the object.
The Structure of Machine Translation Systems
While there have been many variants, most MT systems, and certainly those that have found practical application, have parts that can be named for the chapters in a linguistic text book. They have lexical, morphological, syntactic, and possibly semantic components, one for each of the two languages, for treating basic words, complex words, sentences and meanings. Each feeds into the next until a very abstract representation of the sentence is produced by the last one in the chain.
There is also a ‘transfer’ component, the only one that is specialized for a particular pair of languages, which converts the most abstract source representation that can be achieved into a corresponding abstract target representation. The target sentence is produced from this essentially by reversing the analysis process. Some systems make use of a so-called ‘interlingua’ or intermediate language, in which case the transfer stage is divided into two steps, one translating a source sentence into the interlingua and the other translating the result of this into an abstract representation in the target language.
One other problem for computers is dealing with metaphor. Metaphors are a common part of language and occur frequently in the computer world:
How can I kill the program?
How do I get back into dos?
My car drinks gasoline
One approach treats metaphor as a failure of regular semantic rules
Compute the normal meaning of get into—dos violates its selection restrictions
dos isn’t an enclosure so the interpreter fails
Next have to search for an unconventional meaning for get into and recompute its meaning
If an unconventional meaning isn’t available, you can try using context, or world knowledge
Statistical procedures aren’t likely to generate interpretations for new metaphors.
Interpretation routines might result in overgeneralizations:
How can I kill dos? —> *How can I give birth to dos?
*How can I slay dos?
Mary caught a cold from John —> *John threw Mary his cold.
Catching a cold in unintentional (as opposed to catching a thief)
Getting Started
The best way to learn about language processing is to write your own computer programs. To do this, users will need access to a computer that can display information on the internet. Anyone with an email account on a personal computer has this type of access. The exercises in this class are written for the Perl programming language. This language is widely available on mainframe computers, and allows users to manipulate strings of text with a modicum of ease. In order to use Perl on a mainframe computer, however, the reader will have to access the computer directly via a terminal emulation program.
The only other item that you will need for Perl programming is a text editor. Text editors provide a means of writing the commands that make up a Perl program. Mainframe computers typically have a program that allows users to write text files. You can also use these programs to write a Perl program. The University of Kansas mainframe uses the Pico and vi editors.
Once you have assembled the basic tools for creating Perl programs you are ready to begin language processing. To make sure that you are ready, try doing the following:
1. Open your terminal emulation software, and then login. One way to do this is to click on the run command in the Windows Start menu. Type in ‘telnet’ in the text box and click ‘ok’. This action should open a window in which you can type the command ‘open server’ where server is the name of the computer system on which you have an account. On the computer system at the University of Kansas the server can be accessed by typing ‘open people.ku.edu’ and pressing the ‘Enter’ key. Another way is detailed here. Mac users can open the terminal window and type "ssh user@host" (ex: ssh pyersqr@people.ku.edu).
2. You should see what is called a ‘prompt’ that tells you that you have accessed the main computer system. I assume you have logged onto a computer running the UNIX operating system. A common UNIX prompt is the dollar sign ‘$’. My prompt is ‘raven:/homea/pyersqr$’, which shows that I have accessed my home directory on the raven system.
3. Once you see the Unix prompt, you can see what other files and subdirectories you have in your home directory by typing the command ‘ls’ (the letter ‘l’ followed by the letter ‘s’) and ‘Enter’ (using the ‘Enter’ key on your computer’s keyboard). From here on, I assume that all commands to the computer are followed by pressing the ‘Enter’ key so I will not repeat ‘Enter’ after the command.
4. If you want to switch to one of these subdirectories, you can type the command ‘cd subdir’ where subdir is the name of the subdirectory you wish to switch to. To switch to your mail subdirectory, you can type the command ‘cd mail’. You can switch to a higher directory by typing ‘cd ..’ To return to your home directory from your mail subdirectory type the ‘cd ..’ command. You can also change directly from one UNIX directory to another by typing ‘cd /homedir/userdir/subdir’ where ‘subdir’ is the name of the directory you wish to switch to. Make sure that you use the forward slash (‘/’) rather than the backward slash (‘\’) for this command.
5. You can create a new subdirectory by typing the command ‘mkdir name’ where ‘name’ is the name of the subdirectory you wish to create. You should keep all of your web documents in a folder labeled ‘public_html’. If you do not have such a folder in your directory, you can create it by typing the command ‘mkdir public_html’. The directory name ‘public_html’ is one that KU computers use as the default location for web page documents. Although it appears to be especially cumbersome, saving your web documents in this directory will make it easier to locate them on the web. I suggest keeping all of your Perl files together in a subdirectory of your public_html directory named ‘Perl’. First switch to your public_html directory by typing ‘cd public_html’. Then create the Perl subdirectory by typing ‘mkdir Perl’. After you create this subdirectory, you will need to switch to it by typing ‘cd Perl’. You should then see the UNIX prompt ‘home/user/perl$’. If you want to remove a directory, typing ‘rmdir name’ will delete the directory named ‘name’.
6. If you have gotten this far, give yourself a pat on the back! You have all the tools necessary to begin language programming on the web. In the following weeks, I will show you the basics of creating a web page, and then how to use the Perl programming language to alter web page contents. The bulk of the class will be devoted to using Perl to create programs that process natural language.
Summary of UNIX commands
cd name |
change to a subdirectory |
cd .. |
change to a higher directory |
cd /homedir/userdir/subdir |
change to a different directory |
ls |
display a list of files for the directory |
mkdir name |
make a new subdirectory |
open server |
open a computer server |
rmdir name |
remove a subdirectory |
|
|
Recommended Reading
James Allen. 1995. Natural Language Understanding. Redwood City, CA: Benjamin/Cummings. A comprehensive introduction to field of computational linguistics and natural language processing.
David H. Freedman. 1994. Brainmakers: How scientists are moving beyond computers to create a rival to the human brain. New York: Touchstone. A popular introduction to the field of artificial intelligence.
Hobbs, Jerry R. Computers and Language. SRI International, Menlo Park, CA
Jurafsky, Daniel & James H. Martin. 2000. Speech and Language Processing. Upper Saddle River, NJ: Prentice Hall.
Kay, Martin. Machine Translation. Xerox-PARC, Palo Alto, CA, and Stanford University
Marvin Minsky. 1967. Computation: Finite and infinite machines. Englewood Cliffs, NJ: Prentice-Hall. A more formal introduction to computational theory, but quite readable.
Roger Penrose. 1989. The Emperor’s New Mind: Concerning Computers, Minds, and the Laws of Physics. New York: Penguin Books.
Harel, David. 2000. Computers Ltd.
Wall, Larry, et. all. 1999. Programming Perl
Meyer, Eric. 2000. Cascading Style Sheets
Web References
The Association for Computational Linguistics.